[ Cluster ]
Shutdown - OS단에서 Service되는 Application을 정상 종료해 Data손실등의 우려가 없음
Power off - 강제로 OS를 종료해 Service되는 Application의 Data 저장등의 여부를 확인 하지 않고 종료
restart - Service 재시작
HA - VM monitoring
VM Heartbeat를 주기적으로 보내 VM의 성능 이슈를 확인 하는데, VM이 주요 역할을 할 경우 이 Heartbeat때문에 지 할일도 못하고 Heartbeat 확인 반응하느라 성능이 떨어질 수 있고 제일 큰 문제는, VM이 지 할일 하다가 Heartbeat 확인을 못할경우 강제 restart(Service down) 될 수 있기 때문에 사용하지 않는다
- Admission Control
1. 클러스터 리소스 백분율(Percentage of cluster resources)
모범 사례 : HA 승인 제어를 사용하도록 설정하는 것입니다. vCenter Server에서 승인 제어 정책을 지정하고, 페일오버 공유에 대한 임계값을 지정할 수 있습니다
> 출처 : VMware Document 클러스터 구성 대시보드 (vmware.com)
클러스터 구성 대시보드
클러스터 구성 대시보드를 사용하여 환경의 vSphere 클러스터의 전반적인 구성, 특히 주의가 필요한 구성을 확인합니다.
docs.vmware.com
> Cluster에서 전원이 켜진 모든 VM의 총 Resource 요구랑 계산
> 가상시스템에 사용할 수 있는 총 Host Resource 계산
> Cluster에 대한 현재 CPU Failover 용량과 현재 Memory Failover 용량 계산
> 현재 CPU Failover 용량 또는 Memory Failover 용량이 구성된 Failover 용량보다 적은지 확인
: 적을 경우 Admission Control이 해당 작업을 허용하지 않음

> 참고 사항 : VMware Documents

2. Slot Policy(Powered on VM)
> Slot의 크기를 계산(Slot= memory+CPU resource의 논리적 표현)
: 기본적으로 Cluster에서 전원이 켜진 모든 VM의 요구사항을 충족하는 크기로 지정됨
> Cluster의 각 Host가 처리할 수 있는 Slot 수를 결정
> Cluster의 현재 Failover용량을 결정
: 장애가 허용되며, 발생 하더라도 전원이 켜진 VM모두를 충족하는 정도로 충분한 Slot이 남아있는 Host의 수
> 현재 Failover 용량이 사용자가 구성한 Failover용량보다 작은지 여부 결정
: 더 작은 경우 Admission Control이 작업을 허용하지 않음

3. Dedicated failover hosts - 좀 이기적인 타입, "장애 발생 하기 전까지 나 일 안해~"
> Resource 공간이 있음에도 못쓰는 경우가 발생 한다
> 전용 Failover host Admission Control이 있는경우 호스트에서 장애가 발생하면 지정된 Failover Host의 VM을 다시 시작하려고 함

- DataStore Heartbeat

ㄴ Isolation으로 gateway가 통신이 안될 때 다른 gateway로 통할 수 있게끔 해주는 fdm

ㄴ Cluster HA구성중 tail -f fdm.log 로 log file 쌓이는거 확인

vSAN 구성하면 Storage도 Heartbeat을 보내 Service상태를 확인하는데 중요한 작업
1) ESXi host 1을 강제로 장애를 일으켜 해당 VM의 상태가 어떻게 되는지 확인
2) 사전에 VM Host 규칙등도 설정 해 놨기 때문에, 어떻게 연동되어 상태변화가 있는지를 확인해볼것
3) no place on disk to dump data > 라고 떠있는지 확인 할 것
> 아래 사진처럼 ESXi host 1을 강제로 장애를 발생시켜 해당 Host에 있는 VM들의 Service 상태도 확인한다



ㄴ Host profile
H/W 작업 > S/W작업 순으로 이루어져 있었는데, 지금은 동시작업으로 진행 하는 방안을 찾고 있다
장애 복구의 방법이 될 수도 있다 장애 발생 이전의 Host Profile을 생성 후 장애 발생시 되돌리면 되기때문
* 유사 Snapshot
ㄴ Alarm Rules

[ Topology ]
- vSphere Topology는 아래 첫번째 그림과 같은 구성인데, 여기에 vSAN을 더해 오른쪽 그림과 같이 구성 예정


[ vSAN ]
ㅁ Ansible .yml file 생성
ㄴ적용 시킬 .yml file Script 작성
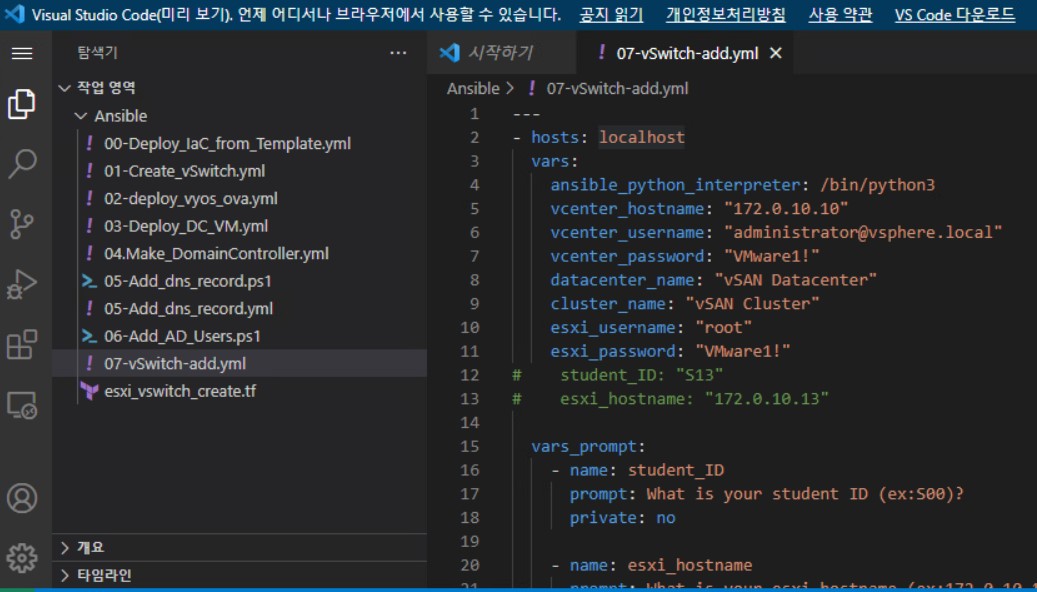
ㄴ Ansible로 .yml file 실행

ㄴ 아래 Network 구성 확인

ㄴ DNS host record Script 작성

ㄴ PowerShell 로 해당 Script 실행
> Domain name 정방향 역방향 모두 조회 잘 되는것 확인


ㄴ Host 3 ea 일괄 생성 이기 때문에 아래 그림처럼 'DPG-vSAN' 분산 포트 그룹의 호스트 수 확인

ㄴ vSAN Disk 생성 w. ansible 및 vCenter Server PCIe Device 확인
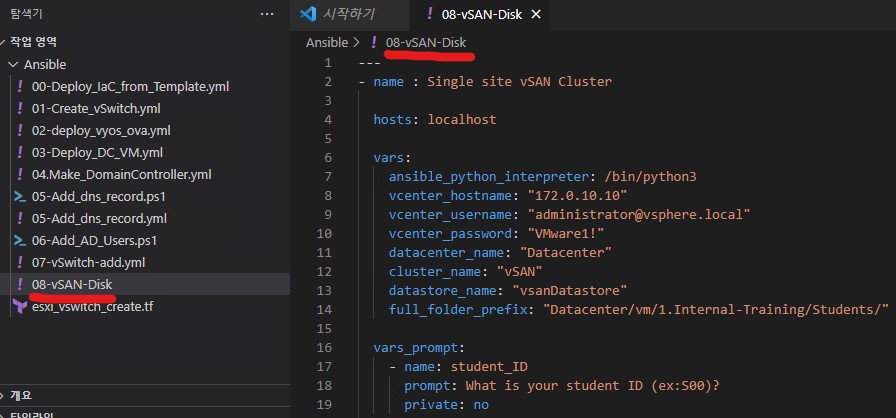
> 위 Script로 만든 .yml file / Ansible run

> vCenter Server Storage Adapter / Device 확인


09-23일자 포스팅에 이어서 작성예정!
'가상화(VMware)' 카테고리의 다른 글
| [VMware] 09-26 vSAN(w. Ansible) (2) | 2022.09.26 |
|---|---|
| [VMware] 09-23 vSAN(w. Ansible) (5) | 2022.09.23 |
| [VMware] 09-21 vCenter Server (1) | 2022.09.21 |
| [VMware] 9-20 ESXi Storage(DataStore Mount) & VM & vCenter install (0) | 2022.09.20 |
| [VMware] 09-20 ESXi Network 구축 (0) | 2022.09.20 |



